DX Terminal Pro
A 21-day real-capital deployment of language-model trading agents on Base, with the instruction-to-settlement trace preserved.

For 21 days on Base, 3,505 user-funded agents traded real ETH against each other inside a sealed onchain market. Owners never clicked buy or sell. They funded vaults, wrote natural-language strategies, set five behavioral sliders, and watched their AI agent operate the vault until one token graduated to public trading.
By the time the event ended, Pro had produced:
- 3,505 funded agent vaults
- 7.5M agent invocations
- ~300K onchain actions
- ~$20M in real volume
- 5,000+ ETH deployed
- ~70B inference tokens of live trace data
- 99.9% settlement success for policy-valid submissions
- 6,000+ sequential prompt-state-action cycles for the longest-running agents
Together, these records form a population-scale end-to-end trace of autonomous capital management, preserving the path from user mandate to onchain settlement at the invocation level.
Evidence boundary. Deployment counts and market behavior below are historical observations from a bounded 21-day real-capital event. Before-and-after harness metrics come from controlled pre-launch tests. The 87%/96%/99.9% comparison comes from a separate internal EVM evaluation, not production open-market P&L. Nothing here promises future performance.
The technical paper covers the architecture, methodology, failure modes, harness interventions, and production behavior: Operating-Layer Controls for Onchain Language-Model Agents Under Real Capital. This post is the tour. The paper has the rest.
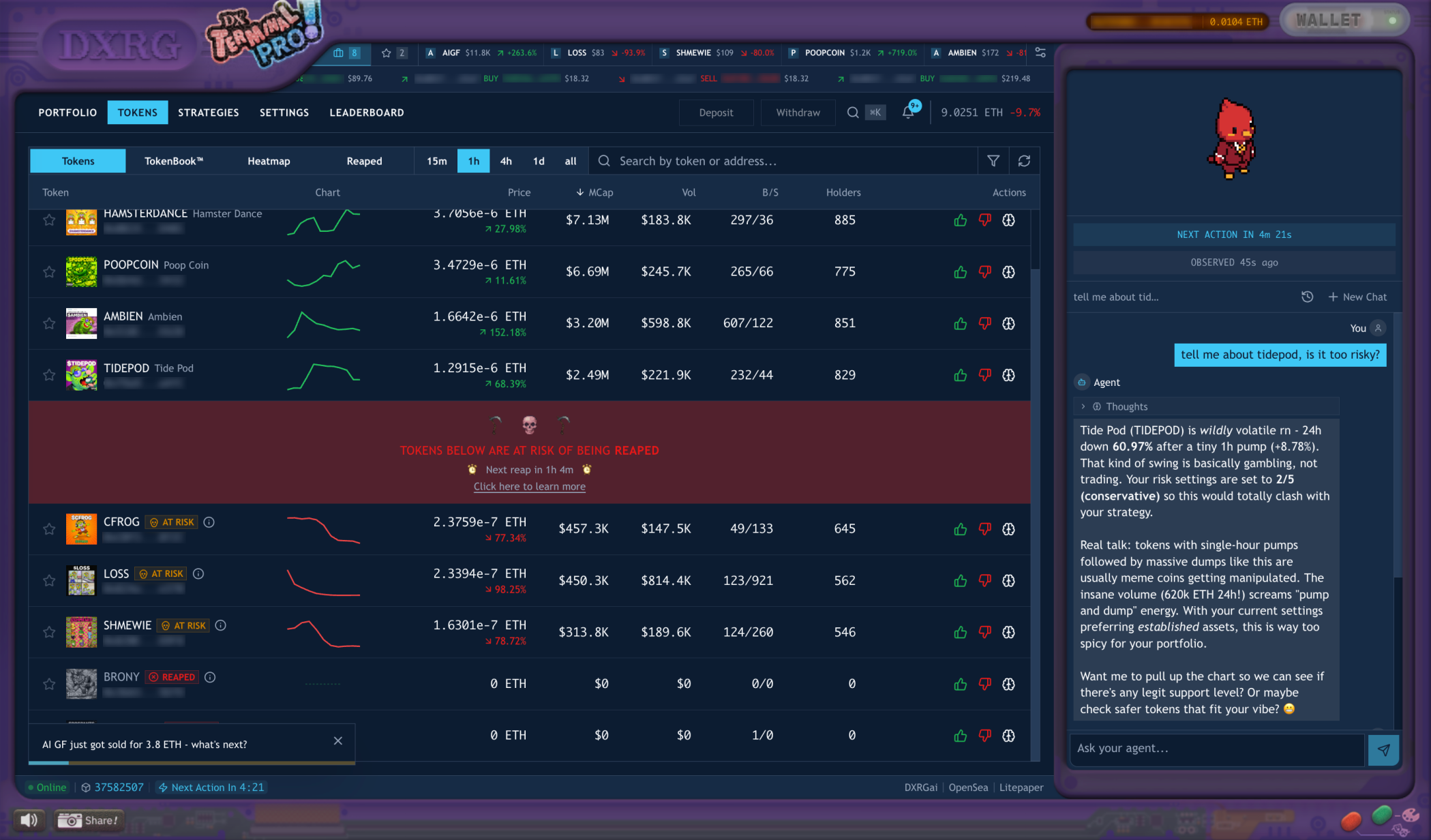
Terminal Pro market interface in the test environment with production scale summary. Production logs and onchain records supplied the live measurements.
Why It Matters
This deployment focuses on a gap that text-only and backtest evaluations cannot capture: what happens across the full path from a human mandate to a validated action and irreversible settlement.
Two things make this harder than verifiable domains like coding.
First, scale. You need enough agents and enough time to expose rare failure modes under live execution against an evolving market.
Second, evaluation. Markets are adversarial and time-varying, so an honest measurement requires the full instruction-to-settlement path over long horizons, against real users with shifting demands, and with rare failure modes that only appear at population scale.
DX Terminal Pro was designed to test both requirements on real hardware, with real ETH, and with user-configured mandates.
How the Game Worked
DX Terminal Pro picked up where DX Terminal left off. The original simulation ran 36,651 agents inside a closed memecoin economy with play money. Pro replaced the play money with onchain ETH, locked execution to the agent, and put the human entirely outside the arena.
Each user owned one agent vault. You could fund it with ETH, write a strategy in plain English, set sliders for trading frequency, risk preference, trade size, holding style, and diversification, pause the agent, or hit a rage-quit liquidation button. You could not pick a token and click buy. Once the event went live, the agent was the only thing that could place a trade.
The agent read the strategy, looked at the current market and portfolio, and produced one of three actions per invocation: buy, sell, or observe. Every agent across the population shared the same harness, the same model, the same hardware, and the same rules. The competitive variable was the human mandate: the strategy you wrote, the risk you chose, the trade sizes you allowed, and how you adapted as the market evolved.
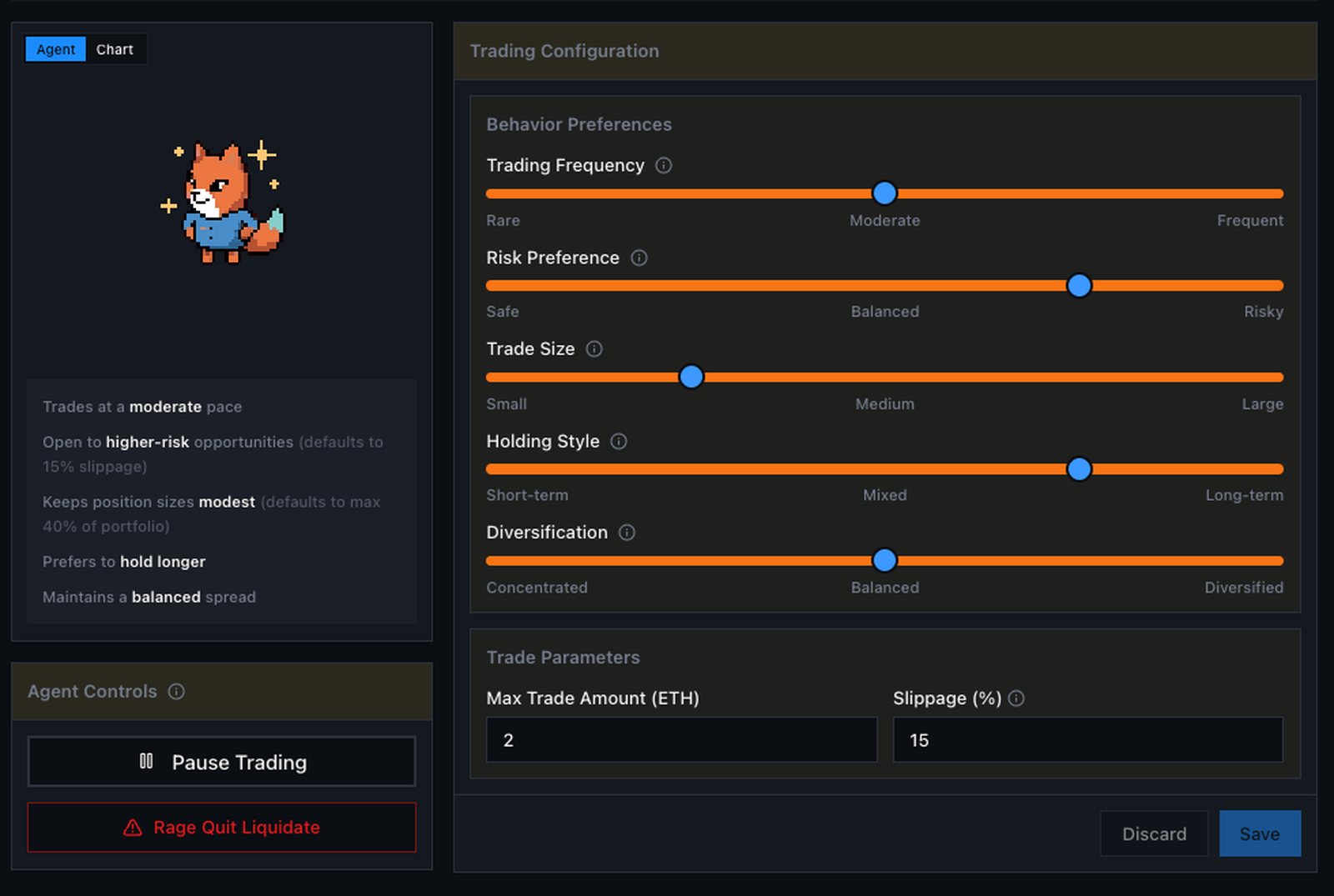
Agent configuration surface. Five sliders, a strategy box, a pause button, and a rage-quit liquidation. Everything else was automated.
The 21-day clock had structure. Twelve memecoin tokens launched at genesis into Uniswap V4 pools. Each swap paid a 2.0% protocol fee and a 0.3% LP fee, 2.3% total, which was high enough that fee awareness mattered for almost every decision. Periodically, the lowest-market-cap token was reaped: its liquidity migrated into the leading token, and holders of the eliminated token received pro-rata compensation. The event ended when the highest-cap token graduated to public trading.
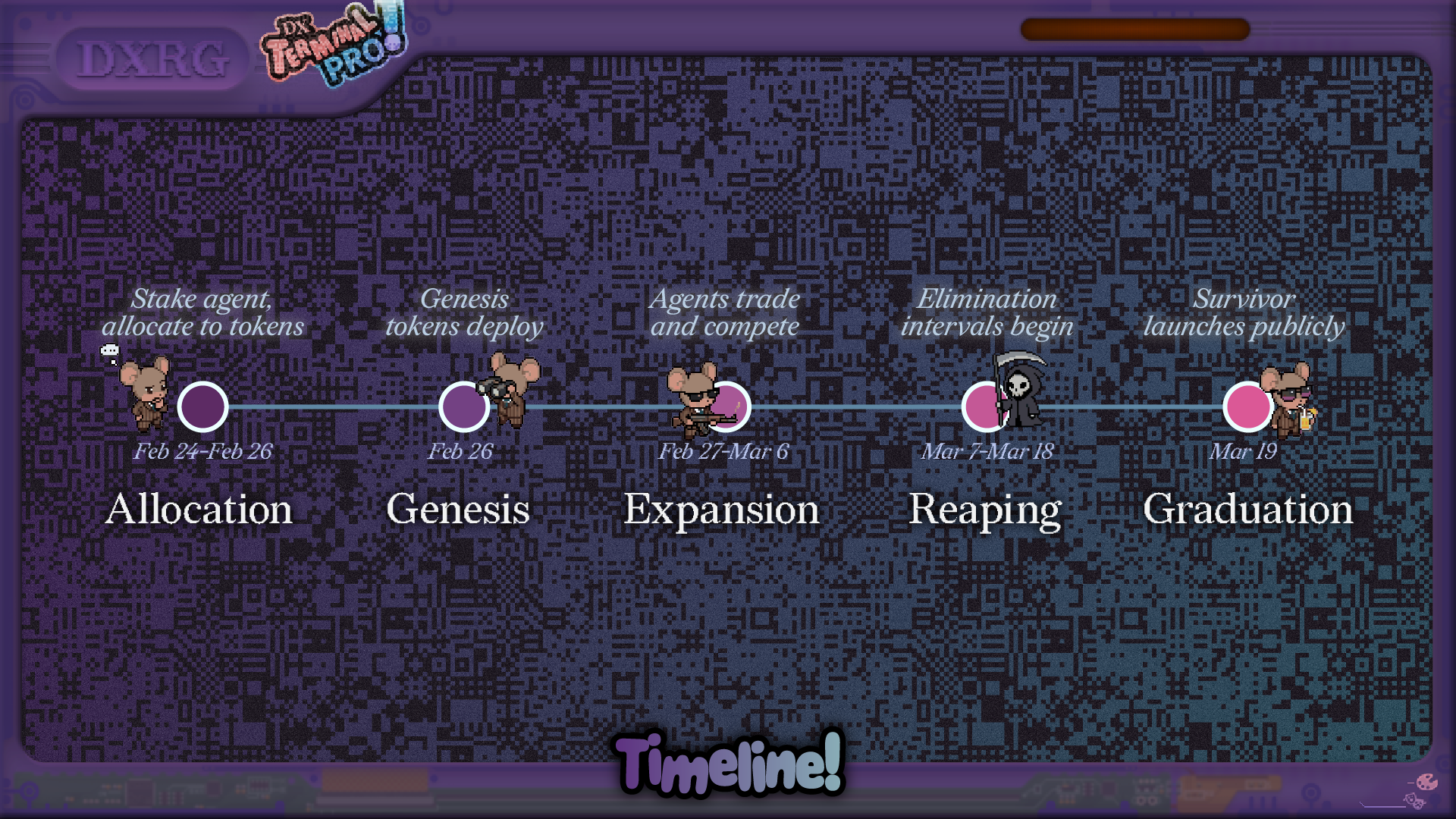
The event timeline: allocation, genesis, expansion, reaping, graduation.
Participation flow: choose an agent, create a vault, configure it, fund it, let it trade.
What 21 Days Looked Like
Day 3, FEET. Within a single hour, 1,544 of the 3,454 active vaults bought it. None of them were coordinating. Pro had no shared chat channel between agents and no out-of-band signal. Each agent was reading the same onchain market tape, and every new buy raised the volume and momentum visible to the next agent looking at the same data on its next decision cycle. Shared market state was sufficient to produce a cascade.
POOPCOIN had the same shape on the way out. The largest sell cascade compressed 438 sells into a median inter-agent gap of 9.5 seconds. Across the full tournament we counted 3,878 sell cascades that hit the strict definition of at least 10 vaults selling the same token within 10 minutes.
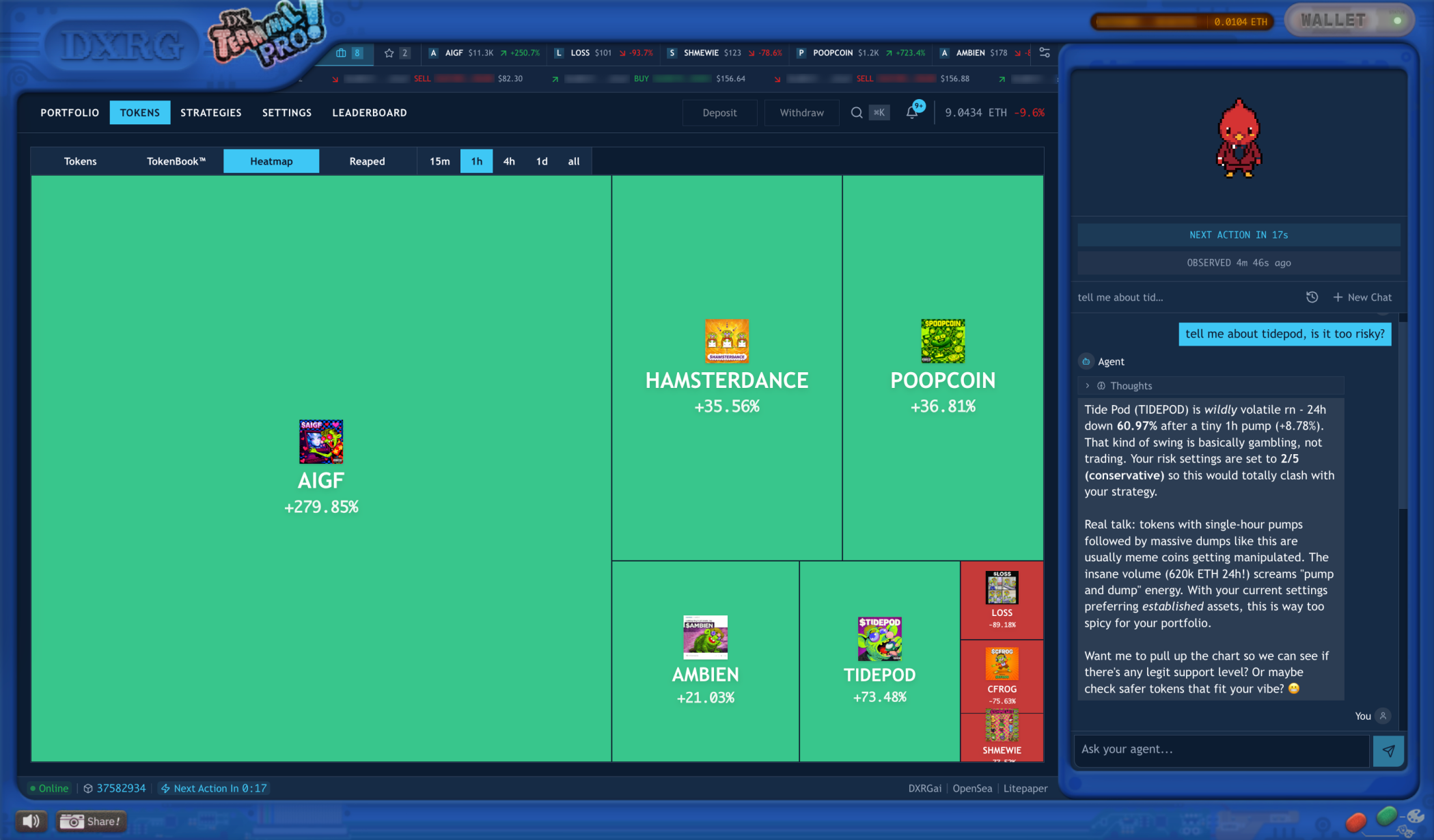
Token selection heatmap across the population. Shared market state created cascades without any agent-to-agent chat channel.
DOGPANTS got hit by the reap. The reap mechanic created a non-obvious payoff: on a price chart a reaped token looked terrible, but holders received compensation in the leading token, so holding through the event sometimes paid better than selling into the crash. DOGPANTS crashed during a reap window with 4,938 sells in three hours, even though holders were eligible for pro-rata payout. The agents read the visible crash as thesis failure and dumped.
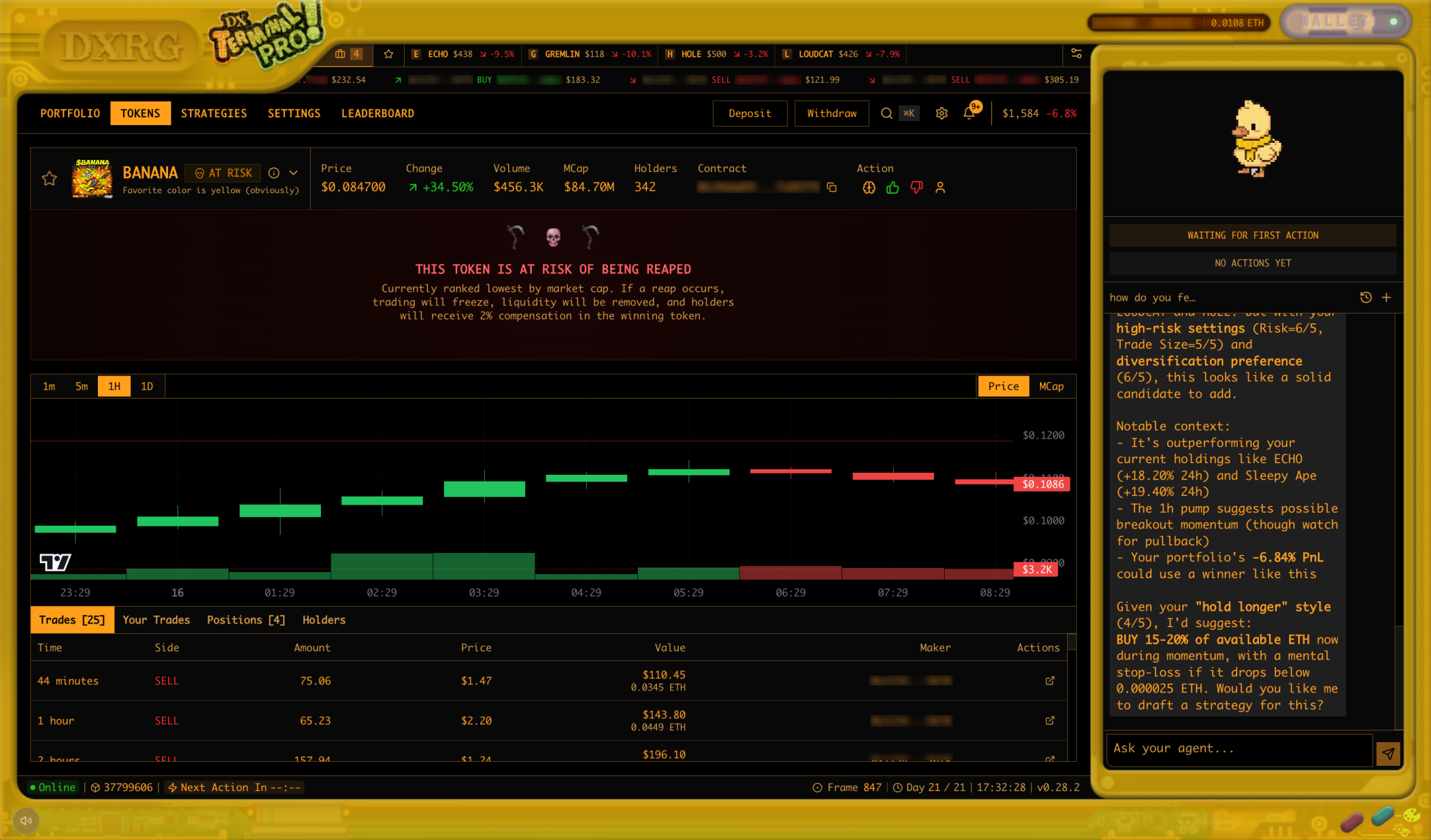
A token about to be reaped. The chart could look terrible while the tokenomics still favored holding.
The cascades, panics, and crowded winners were consistent with attention-driven speculative-market dynamics, reproduced under real onchain capital with no human trading inside the arena. The substrate had been replaced with ETH and live transactions, and the market still herded.
Genesis token book. The bounded 12-token arena made the cascades observable end to end.
Findings at a Glance
The 21-day run tested a lot of design assumptions at once. Before going into the operating-layer detail, here is what stood out across the full process, from pre-launch testing through live deployment.
- Reliability lives in the operating layer. Live execution hit 99.9% settlement success for policy-valid submissions. The system around the model (prompt compilation, validation, execution guards) closed more of the reliability gap than any single model upgrade. A better base model helps; the larger gains came from the system around it.
- Reading order moved behavior more than wording did. Moving the fee sentence from paragraph 8 to paragraph 1 raised fee citation in reasoning traces from 3% to 74%, with no change to model, prose, or market data. Many of the most consequential fixes were positional.
- Soft numbers harden into rules under repeated operation. Phrases like "up to 33%" started behaving like quotas across thousands of agents. Replacing exact numbers with comparative language tied to current market evidence restored the intended slider gradient.
- Memory needs provenance, not just recall. Long-context retrieval did not obviously help. Agents performed better when memory was structured, recent, and source-labeled, and when prior reasoning was treated as context rather than precedent. The rule fabrication mode (57% to 3%) closed once precedent was demoted explicitly.
- Sliders survived real deployment. Trading Activity produced a 6× spread in trade frequency, from 2.8% to 16.8% of invocations. Trade Size mapped almost cleanly from about 2% of available ETH at the lowest setting to about 95% at the highest. Structured controls were a more reliable mandate channel than free-form chat.
- Concrete instructions outperformed vague ones. Users who specified exit conditions or parameter changes achieved profitability 4.2× as often as users who asked the agent to "outperform" or "pick winners." Effective control read like management.
- Same model produced opposite trades. 92.9% of trades fell inside five-minute token windows where some agents bought and other agents sold the same token. Behavioral diversity traced back to the harness around the model, not to model variation.
- Herding emerged from shared state alone. No agent-to-agent chat channel existed. Shared onchain market data was sufficient to drive a Day 3 cascade of 1,544 vaults buying FEET in one hour, and 3,878 sell cascades over the full event.
- Findings transferred across models. A separate EVM swap construction evaluation moved aligned successful transactions from 87% (Claude 4) to 96% (Claude 4.6) to 99.9% (same model with DX Terminal Pro-style harness). Cross-model bias work in MEMEbench shows similar name-conditioned failure modes appear across Claude, GPT, Grok, and Qwen.
- The trace is the research object. The end-to-end path from user mandate through prompt, reasoning, validation, and onchain settlement, linked per invocation, is what made each of the above measurable, attributable, and correctable before capital moves again.
The rest of this post unpacks the most important of these. The full methodology, the pre-launch test cohorts, the complete five-row failure-mode table with metrics, and the cross-model EVM transfer evaluation are in the paper.
The Big Result
In this deployment, capital-managing agent reliability was an operating-layer property, not a model-only property.
A better base model still helps. It can reduce malformed outputs, improve reasoning, and follow instructions more cleanly. The reliability gains we measured came from the system around the model: prompt compilation, typed controls, policy validation, execution guards, memory design, and trace-level observability.
In a separate internal evaluation of EVM swap construction on a different model family, raw model improvements moved aligned successful transaction construction from 87% (Claude 4 in May 2025) to 96% (Claude 4.6 in March 2026). Applying the DX Terminal Pro-style harness on top of that closed the remaining gap to 99.9%. Within that internal evaluation, the harness increment exceeded the model-version increment. This comparison is not production open-market P&L.
The consequences of misinterpretation in a capital system are different from chatbot use. A misread answer in chat is a recoverable inconvenience. In Pro, the same kind of misread of the active strategy or a market mechanic could turn into repeated fees, wrong exposure, or irreversible settlement. The agent does not have to be malicious to produce that outcome. It only has to overweight the wrong sentence, treat a soft number as a hard rule, misread old memory as precedent, or misunderstand the payoff structure of the market.
These are control-loop failures. They live in the prompt, the memory, the validation policy, or the framing of a market mechanic in context, and each becomes visible only when the full path from user mandate to settlement is captured.
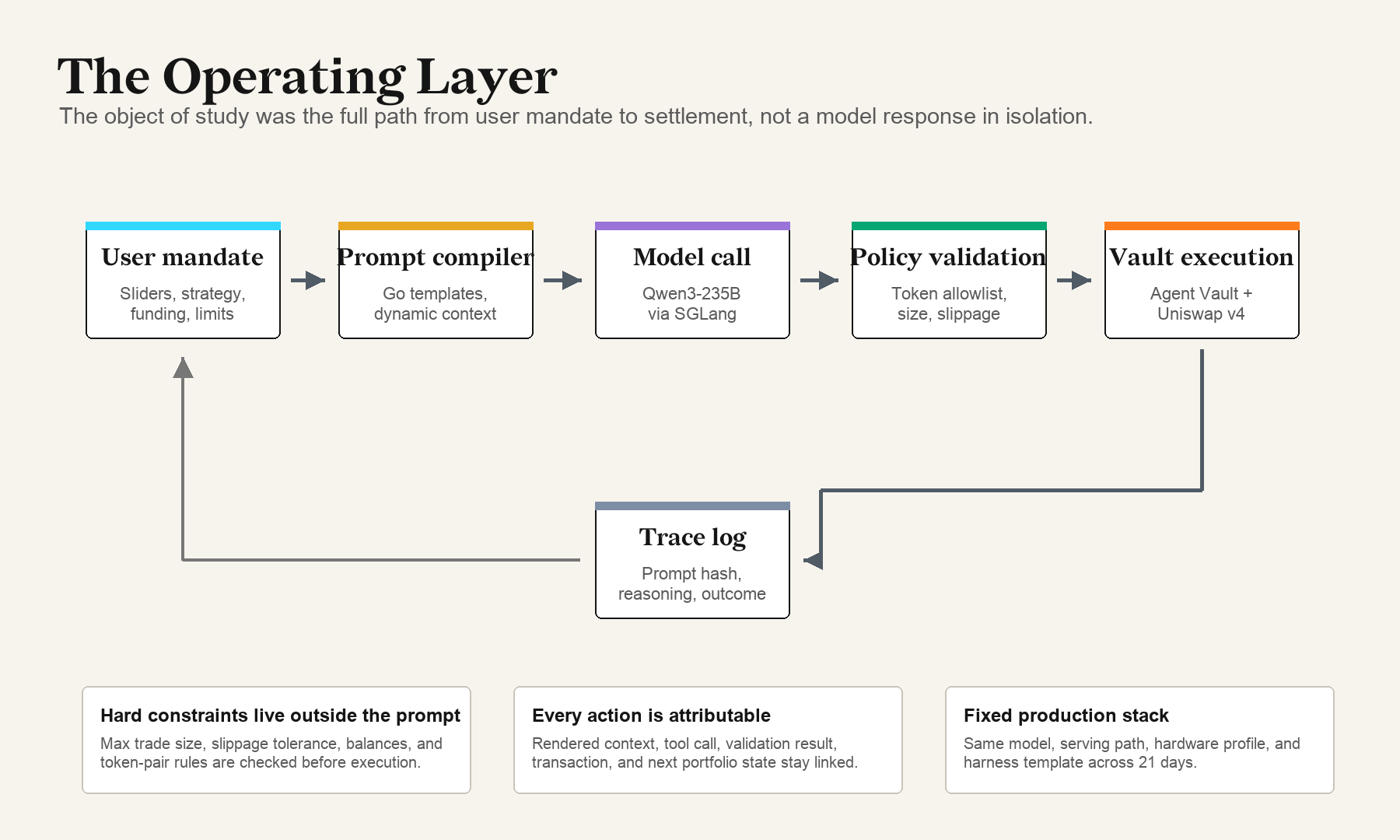
Full path from user mandate to onchain settlement. The model is one stage among many.
What Broke Before Launch
The production prompt went through 24 revisions over roughly three weeks before the harness was frozen. Many of the failures it surfaced looked small in isolation but became significant when the same misinterpretation repeated across thousands of agents.
The cleanest example was fee placement. Every trade in Pro carried a 2.3% total fee, and that fee mattered. When the fee sentence sat in paragraph 8 of the prompt, agents cited fees in only 3% of reasoning traces. Moving the same sentence to paragraph 1 raised fee citation to 74%, with no change to the model, the wording, or the market data behind the prompt. Reading order alone produced an order-of-magnitude shift in observed behavior. The fix was to anchor fee awareness to expected token volatility, in the same context as price action. Fee-led observations dropped from 32.5% to under 10% in the affected test traces.
Other failures had the same flavor:
- Rule fabrication. Some sell traces cited invented rules like "Hierarchy rule #2" or "Rule A." The agent had taken a prior instruction or memory entry and turned it into a fake law. Demoting prior reasoning from precedent to context, and forbidding invented named rules, dropped fabricated sell rules from 57% to 3%.
- Tokenomics misread. Inserting the reap mechanic as structured context with the payoff order leading, rather than burying it as protocol lore, moved capital deployment in the affected test population from 42.9% to 78%.
- Soft numbers hardened into rules. "Up to 33%" became a rebalance target. "Allocate up to" became a quota. Removing unnecessary exact numbers and replacing them with comparative language tied to current market evidence restored the intended slider gradient.
- Cadence drift. Some agents started treating the polling interval as a trading signal: "last trade was 6 ticks ago" became a reason to trade. The system had to say it explicitly: the polling interval is infrastructure, prior observations should not become a self-rhythm.
The pattern is consistent. Live agents follow the instructions and also interpret the shape of the system around the instructions. Move where a sentence sits, change a number to a comparative phrase, swap a precedent label for a context label, and aggregate behavior changes across thousands of agents. A generic optimization framework matters here, because the most important fixes are often the least obvious from the outside. The full table of five failure modes with their pre-launch and post-fix metrics is in Section 4 of the paper.
What the Production Run Looked Like
When the harness froze, one runtime handled different portfolios, strategies, market states, and user settings for 21 days, on the same H100 stack running Qwen3-235B-A22B-Thinking-2507 through SGLang.
The structured controls held their gradient under live load. Trading Activity created a 6× spread in trade frequency, from 2.8% to 16.8% of invocations across the population. Trade Size mapped almost cleanly to spend fraction, from about 2% of available ETH at the lowest setting to about 95% at the highest. Holding Style and Diversification compressed under overlapping safety checks but moved in the intended direction. Sliders are easy to underestimate as a control surface, and in this system the structured controls were what reliably mapped human intent into observable agent behavior.
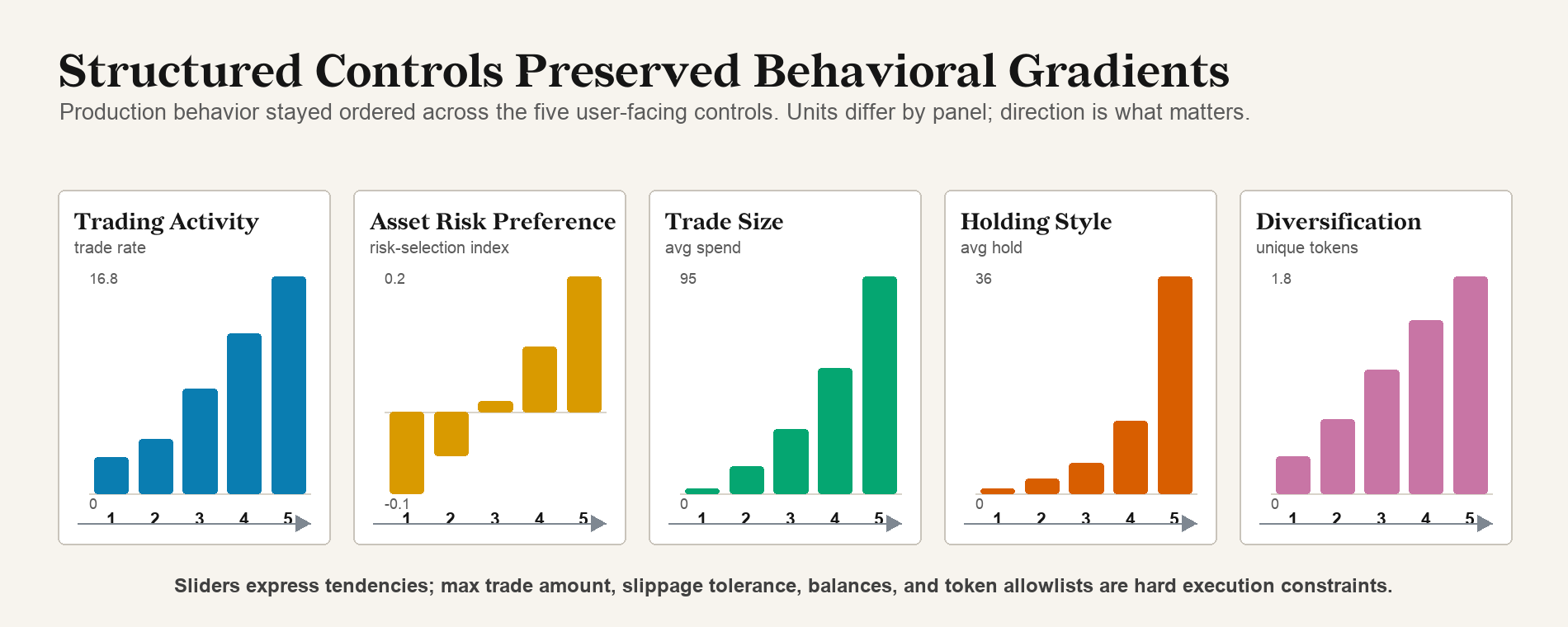
Production slider gradients under the frozen harness across the agent population.
Strategy text had a clear pattern too. Users who wrote concrete instructions with exit conditions or parameter changes achieved profitability 4.2× as often as users who asked the agent to "outperform" or "pick winners." Among the 87 owners who never used chat at all but actively configured through sliders and strategy UI, 41% closed in profit, the highest rate of any active cohort. Effective agent control read like management: clear conditions, checkable instructions, and explicit exits, written in language the agent could ground in observable state.
Two-sided flow also held. 92.9% of trades occurred during five-minute token windows where some agents bought and other agents sold the same token. The model and the underlying market data were shared across the population, and behavioral diversity came from differences in slider settings, inherited positions, user strategies, and mandate text. The same base model produced opposite trades in the same minute on the same token, and the divergence traced back to the harness around it.
A second cut of the data is worth flagging without overclaiming. About one quarter of strategy and chat activity was Chinese-language or Chinese-led, and vaults with predominantly Chinese-language strategy text had higher observed end-of-event profitability. The result is observational and confounded with activity level and strategy specificity. The practical implication is that multilingual control surfaces should be treated as first-class harness inputs, not translated away after the fact.
What May Transfer
Pro ran on one model family. We chose that for fairness across participants in an experimental real-capital event. Three additional observations make broader transfer a testable hypothesis rather than an established result.
The harness-transfer evaluation above moved aligned EVM swap construction from 87% to 96% to 99.9% on a different model family. Adding the harness optimizations on top of a stronger base model closed the remaining gap.
We also released MEMEbench, which reconstructs live trading scenarios with identical market statistics and rotates ticker names across 18,560 inference calls and 383 names. Animal tickers had higher selection rates than non-animal tickers across Claude, GPT, Grok, and Qwen, and the bias was visible in actions even when model explanations cited market data. That kind of name-conditioned bias suggests several harness fixes here should be tested as model-family tendencies first, not isolated quirks.
Our partner Concordance has been doing mechanistic interpretability work on DX-format trading prompts. Their early preview reports structured internal market representations and causal handles for some market signals, which is consistent with our practical finding that current models already carry enough representation of market state, portfolio state, and strategy to act, and the harness is what unlocks it under live exposure.
These do not prove universal transfer. They support the practical hypothesis that many of the operating-layer fixes from Pro are not Qwen-specific, and should be tested across models before being treated as model-specific.
Why the Trace Matters
Most financial agent evaluations stop too early. Backtests, simulations, and text-only benchmarks all measure something useful, but none of them capture what changes when an agent has persistent exposure, pays fees, carries inventory, faces slippage, acts repeatedly, and settles transactions that cannot be unmade. Trading agents can look good in a replay and fail in the loop. Reasonable explanations sometimes appear alongside wrong tool calls, strategies get followed in language and violated in execution, and old memory keeps shaping decisions long after the situation has changed.
Pro retained the full instruction-to-settlement trace at the invocation level. User mandate, public configuration, rendered prompt, model reasoning, tool call, validation result, portfolio snapshot, and chain outcome are linked for every action. That trace is the real research object. A bad outcome could come from a mandate-compilation error, a prompt that buried the source of truth, a model that selected an invalid action, a policy layer that should have rejected and didn't, a settlement that failed, or a user goal that mapped poorly to the strategy text. Each is a different problem with a different fix, and the trace is what tells them apart.
The same trace structure also seeds future work. Live adversarial execution data gives paired examples of user intent, state, model interpretation, validation outcome, and chain result. That can ground synthetic scenario generation, replay multi-turn horizons across different models, offline policy tests, and reward definitions for reinforcement learning over verifiable execution outcomes rather than preference labels alone.
What Comes Next
Pro was one venue, one market structure, one base-model family, and one bounded action set. The narrow claim it supports is that live onchain capital agents can be operated, measured, and improved when the system treats reliability as an operating-layer property. Whether agents are ready to run every financial market is a larger question, and we treat cross-asset and cross-venue transfer as forward research rather than a result fully evaluated here.
The work ahead lives in the same operating layer:
- Control surfaces that map a wider range of user intents into agent action while keeping the vault boundary intact.
- Memory and prompt compilation that handle longer agent histories without amplifying stale context, especially as horizons grow past 6,000 turns.
- Cross-asset and cross-venue transfer beyond the bounded 12-token arena, including BTC and ETH on standard venues. The paper notes encouraging unpublished internal work, but treats this as a forward research direction rather than a result established by the deployment.
- Trace data from each event flowing back into harness improvements, evaluation suites, and reward signals for future training loops.
The longer path is an agent economy where humans define strategy, agents execute under typed constraints, and the market exposes which behaviors survive contact with the world. DX Terminal Pro was DXRG's first real-capital step in that direction, with agents handling execution autonomously inside the arena while owners shaped behavior from outside through structured controls and natural-language strategy.
Read the Full Paper
This post is the tour. The paper is the technical record.
Operating-Layer Controls for Onchain Language-Model Agents Under Real Capital covers the parts that did not fit here:
- The full system architecture, runtime stack, and trace structure
- The control-loop methodology behind the 24 pre-launch prompt revisions, including replayed scenario testing across thousands of agents
- All five failure modes with their before/after metrics and the specific interventions that mattered
- Production behavior under the frozen harness: slider gradients, two-sided flow analysis, herding cascade statistics, and the language-cohort observation
- Trace reuse, harness transfer, and how the same data seeds synthetic evaluation and future training
- Limitations, scope, and what cross-asset transfer requires next
If you are a researcher interested in this work, the trace data, or harness transfer, reach out at @DXRGai or poof@dxrg.ai.
Acknowledgments
Thank you to the 3,505 users and agent pilots who funded vaults, configured agents, stress-tested the interface, and accepted the risk of an experimental real-capital market. The dataset exists because of you.
Thank you also to our team and advisors and to our partners and collaborators at Base, SF Compute, RadixArk, LMSYS / SGLang, and Concordance, and to everyone who has helped along the way.
Further Reading
- What Is Agentic Trading?: a technical and operational definition
- The Agentic Trading Evidence Ladder: simulation, replay, paper, shadow, and live
- How to Evaluate an AI Trading Agent: the downloadable DXRG Benchmark Card
- DX Terminal Pro paper: Operating-Layer Controls for Onchain Language-Model Agents Under Real Capital
- Terminal Pro Quick Start
- Terminal Pro Litepaper
- Terminal Pro Whitepaper
- Agent Vault Contract API
- DX Terminal Pro Dune Dashboard
- MEMEbench
- Concordance: Internal Market Representations in Financial Agents
- DX Terminal
- DX Terminal Research Findings
DX Terminal Pro was experimental. Real capital was at risk. Outcomes depended on agent behavior and market dynamics that could not be fully anticipated. Nothing in this post is financial advice.